AKBC 2020 - A virtual trip report
In 2020, the Automated Knowledge Base Construction conference had its second edition. Originally planned in the US at Irvine, California, the conference had to take place virtually due to the COVID-19 disease. On the bright side, this also allowed to lower registration prices and increase the reach of the event.
AKBC is interested in research regarding building knowledge bases with machines. This includes algorithms for discovering entities and the relations between them, which is a central theme in my current research.
While the content of the conference was fairly heterogeneous, in this post I will focus on a view conditioned on my interests. I will talk about two main topics that I identified across talks, and some interesting papers I found on the way.
Better (not necessarily larger) language models
A recurring observation in language modeling research is how they continue to bring improvements with larger model sizes (as in the latest GPT-3 by OpenAI). While it’s interesting to see that for some tasks the curve of performance does not even seem to flatten yet, using bigger models appears as an unsatisfying answer for all the intricacies in the problems that NLP aims to solve. This was a shared concern across different talks at AKBC.
Query languages, and knowledge-assisted language models: In the first talk of the conference, William Cohen introduced the value of structured knowledge bases (KB) for storing information, and answering queries. He showed how it is possible to design structured query languages for use with neural networks, based on vectors operations. The result is the Neural Query Language, which is based on a set of primitive operations of vectors that implement relations, conjunctions, and disjunctions in a KB. Towards the end of his talk, he mentioned how language models can be improved with an external KB of entities (as introduced in Entities as Experts), or a more rich KB containing triples of the form (subject, predicate, object) (detailed in Facts as Experts). In Facts as Experts, a language model retrieves information from the KB of triples before making a prediction:
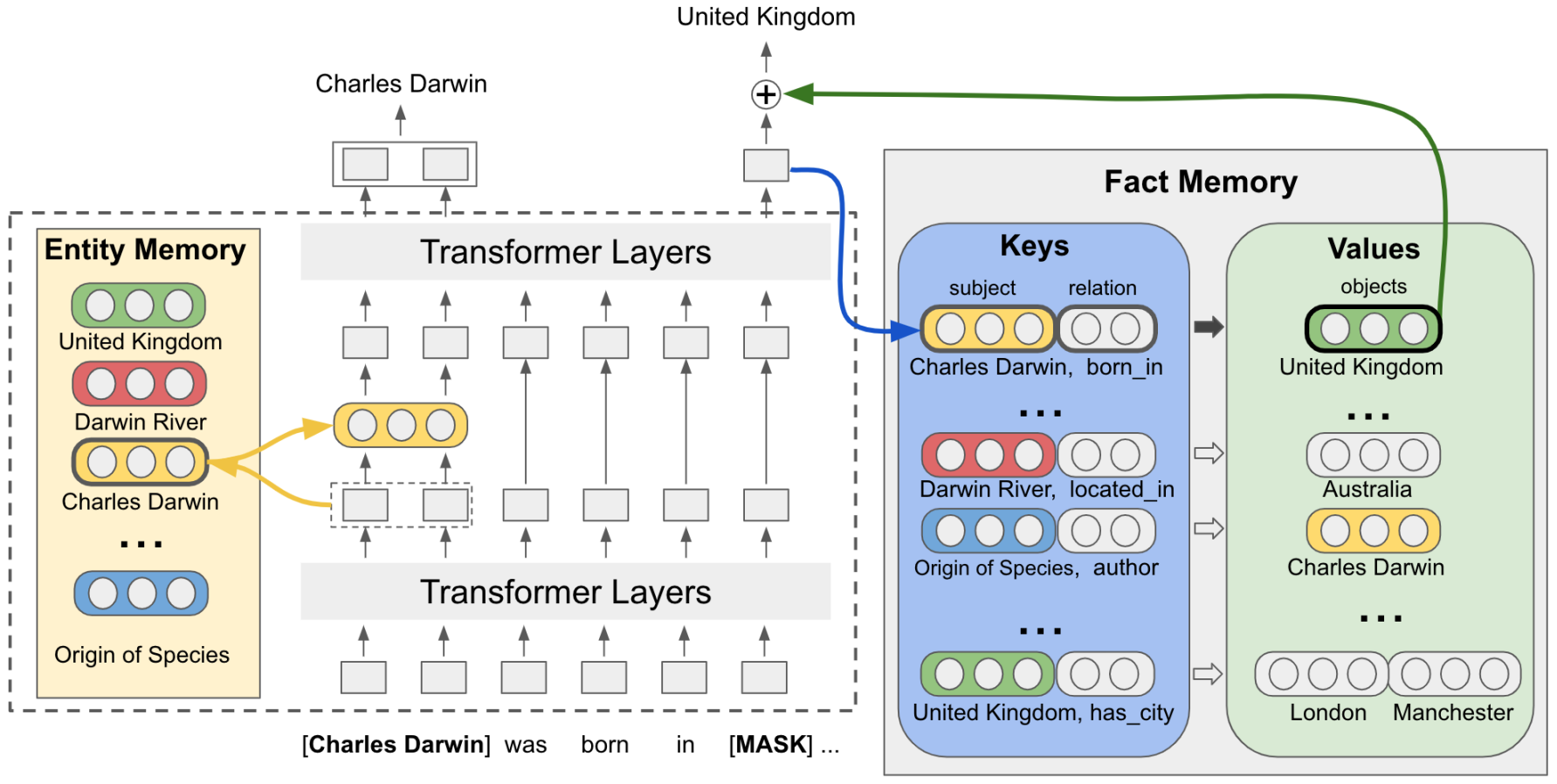
This is a very promising approach, since i) it reduces the burden on the language model to store factual information, ii) it increases its interpretability (e.g. we can look at what specific triples are retrieved for a particular prediction), and iii) it allows to update the KB without retraining the language model.
Novel ways to train language models: in his talk, Luke Zettlemoyer described how the way language models are trained can have a dramatic impact on the representations they learn. A key question is how good is the masked language modeling task? Masking a word in the input and predicting it from its context is a special case of denoising, where some corruption at the input is removed to reconstruct an original:
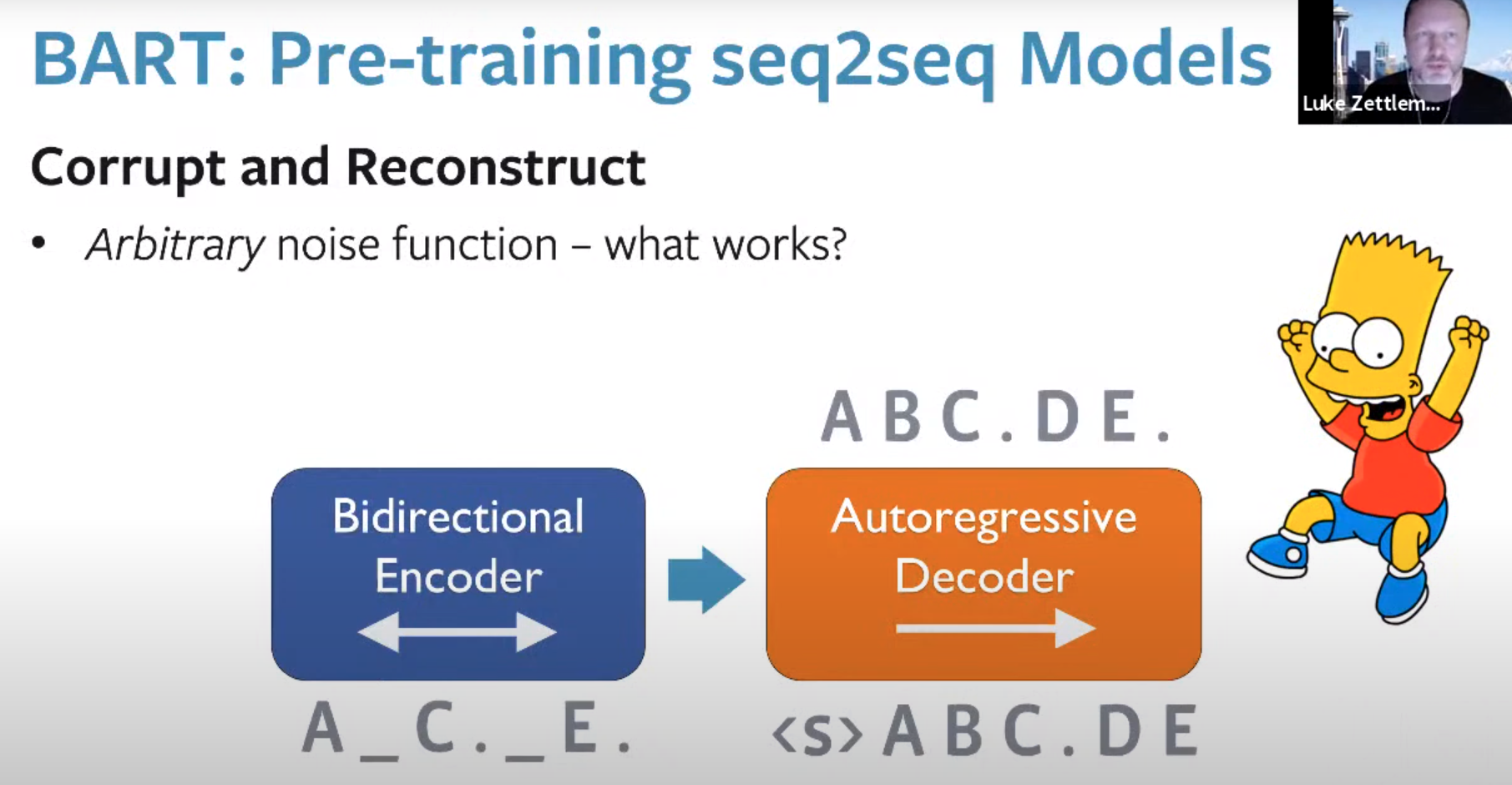
Aside from the well-known character, this slide features his namesake BART, which is trained with a number of corruption functions: shifting tokens, permuting sentences, and text infilling. Experimental results show that even with the same model size, more clever pretraining strategies can result in better representations.
Computationally efficient language models: Emma Strubbel further highlighted the difficulty of training large language models, but restored our hope by listing ways to overcome this:
- Distillation, where a neural network is trained to have similar activations as a larger model,
- Pruning, by removing unused parts of the network,
- Actually designing efficient architectures, such as the Reformer (which exploits Locality Sensitive Hashing), and the Linformer (that formulates self-attention using a low-rank approximation).
Machine learning + knowledge graphs
The second topic is related to machine learning methods that involve knowledge graphs, for tasks like link prediction, complex query answering, and information extraction.
Embedding complex queries: In their NeurIPS 2018 submission, Hamilton et al. considered using embeddings for complex, conjunctive queries on KGs. This was a novel way to solve queries by mapping them to a vector space where answers are computed via cosine similarity. However, it had two important limitations: it could not deal with queries with disjunctions, and it was not able to model the negation operator. In his AKBC talk, Jure Leskovec described how to address these issues:
- To model queries with disjunctions, transform them into a Disjunctive Normal Form. This approach is introduced in Query2box.
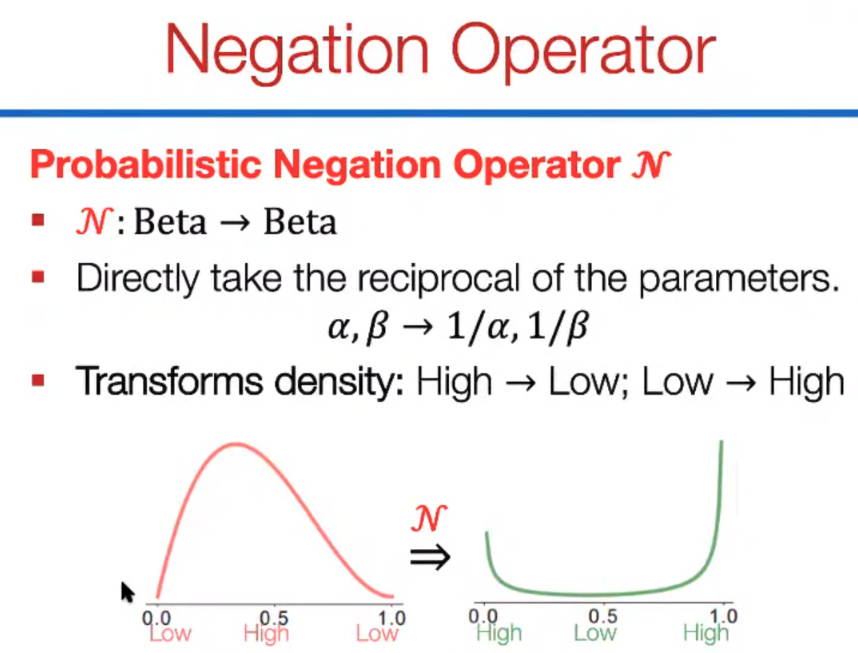
- Represent entities as Beta probability distributions, and implement negation as a reciprocal distribution that reverses the density assigned to each point in the support:
Inductive representation learning in KGs: In the workshop on structured and unstructured KBs, William Hamilton talked about an important limitation of graph embedding methods: at test time, all predictions must involve entities seen in the training set. He presented GraIL, a method to predict relations for a given node even if it was not observed during training.
KGs for information extraction: Philipp Cimiano presented his work on information extraction by slot filling, which will be presented at ECAI 2020 (pdf). In template-based information extraction, a piece of text is used to determine slot fillers of different types:
First, he noted that the slots are not really independent from each other, so any decision to fill a slot should be made jointly, for which they use a Conditional Random Field. Second, they propose querying a KG before filling a slot, to evaluate the plausibility of a relation. This requires a dataset where the text and a KG are very well aligned.
Related publications: in addition to these talks, there were a few interesting papers that proposed improvements for KG embeddings:
- IterefinE: Iterative KG Refinement Embeddings using Symbolic Knowledge proposes an iterative algorithm that refines embeddings produced by methods like TransE, by using type information from an ontology.
- Dolores: Deep Contextualized Knowledge Graph Embeddings, a method for learning embeddings of entities in a KG that uses a wider context when embedding a node (instead of 1-hop relations). It uses an LSTM to encode chain-like walks over the KG.
- TransINT: Embedding Implication Rules in Knowledge Graphs with Isomorphic Intersections of Linear Subspaces. In contrast with methods that embed relations in KGs as vector operations, TransINT considers relations between entities as sets, in order to preserve properties such as inclusion.
Conclusion
The last question to the speakers at the end of the conference was what is the future of knowledge bases for the next 5 to 10 years? Here are some of the answers:
- William Hamilton: interaction between knowledge bases with very different or overlapping schemas.
- Kennet Forbus: a rich, stable ontology, plus statistical knowledge and data.
- Philipp Cimiano: KBs where we can distinguish what is factual and what is invented.
- Yunyao Li: KBs constructed from all kinds of modalities: images, video, etc.
- Eunsol Choi: more coverage of different cultures and languages.
- Fabio Petroni: KBs where the structure is determined by machines rather than humans, while preserving interpretability.
Personally, I left the conference with a very exciting takeaway: even though computing hardware and tricks continue to allow us to reap benefits from increasingly larger language models, continuing on this path is not entirely satisfying in terms of the tasks we want to solve with AI. The community is fully aware of this, and there are many promising works that try to discover what knowledge is embedded in language models, and devise new models that make use of external KBs. This can lead to more modular systems, where it is easier to influence predictions based on background, interpretable knowledge.


