Transforming distributions with Normalizing Flows


Probability distributions are all over machine learning. They can determine the structure of a model for supervised learning (are we doing linear regression over a Gaussian random variable, or is it categorical?); and they can serve as goals in unsupervised learning, to train generative models that we can use to evaluate the probability density for any observation, or to generate novel samples.
Normalizing Flows are a particular mechanism for dealing with probability distributions, that continues to receive increased attention from the machine learning community. Just a few weeks ago, a whole workshop was devoted to them (and some related methods) at the ICML 2020 conference. So what are Normalizing Flows and why should we care about them?
In this post I will attempt to answer this question, covering
- An introductory description of NFs and their applications
- A basic implementation using PyTorch
- The results after training a model for density estimation with NFs
This notebook runs in under 20 seconds in CPU, on a laptop with an Intel Core i7 processor, so I’d highly encourage you to run it and tinker with it (click on the button above to go to the repository).
Normalizing flows are based on a fundamental result from probability theory. Assume $\textbf{u}$ is a vector in a d-dimensional space $\mathbb{R}^D$, obtained by sampling a random variable with probability density $p_u(\mathbf{u})$. A normalizing flow is a differentiable transformation $T$ with inverse $T^{-1}$, such that if we pass $\mathbf{u}$ through $T$, we get another vector $T(\mathbf{u}) = \mathbf{x}$ in $\mathbb{R}^D$. Since $\mathbf{u}$ is a sample from a random variable, it follows that $\mathbf{x}$ is also a sample from another random variable. It turns out that the density of the transformed random variable can be computed as
\[p_x(\mathbf{x}) = p_u(\mathbf{u})\left\vert \text{det } \mathbf{J}_T(\mathbf{u}) \right\vert^{-1}\tag{1}\]In this formula, $\mathbf{J}_T(\mathbf{u})$ is the Jacobian of the transformation $T$ with respect to $\mathbf{u}$. This is a $D\times D$ matrix that contains all partial derivatives of the elements in $\mathbf{x}$ with respect to all elements in $\mathbf{u}$:
\[\mathbf{J}_T(\mathbf{u}) = \begin{bmatrix} \frac{\partial T_1}{\partial u_1} & \dots & \frac{\partial T_1}{\partial u_D} \\ \vdots & \ddots & \vdots \\ \frac{\partial T_D}{\partial u_1} & \dots & \frac{\partial T_d}{\partial u_D} \end{bmatrix}\]The above fact is particularly interesting if $p_u(\mathbf{u})$ is a distribution for which we can easily evaluate the density (such as a Gaussian distribution), and $T$ is a flexible transformation that can potentially produce a more complicated density $p_x(\mathbf{x})$:
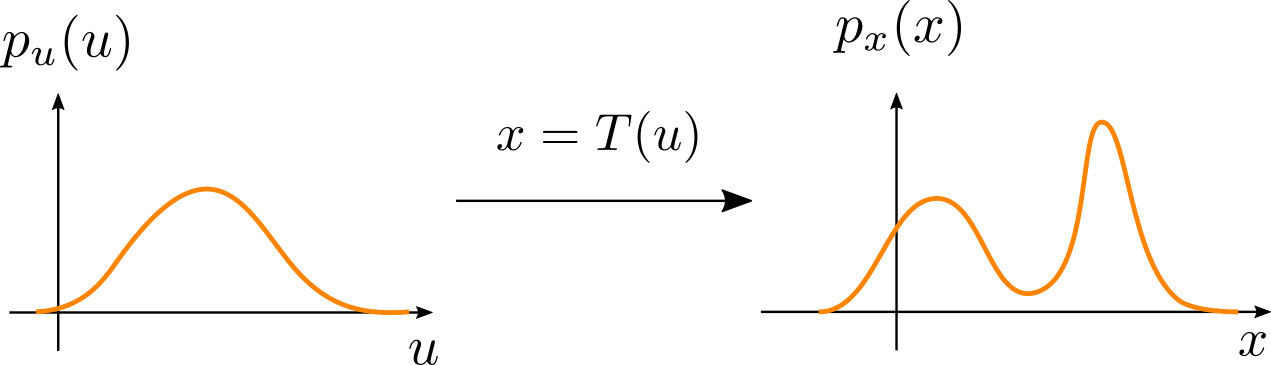
What is interesting is that we don’t need explicit access to the transformed density to evaluate it for any $\mathbf{x}$. Instead, following eq. 1, we can transform $\mathbf{x}$ back to $T^{-1}(\mathbf{x}) = \mathbf{u}$, evaluate the density with $p_u(\mathbf{u})$, and multiply the result by the Jacobian of the inverse:
\[\begin{align} p_x(\mathbf{x}) &= p_u(\mathbf{u})\left\vert \text{det } \mathbf{J}_T(\mathbf{u}) \right\vert^{-1} \\ &= p_u(T^{-1}(\mathbf{x}))\left\vert \text{det } \mathbf{J}_{T^{-1}}(\mathbf{x}) \right\vert \end{align}\]In fact, we can specify $T$ as a composition of $K$ differentiable, invertible transformations $T = T_K \circ\dots\circ T_1$, to obtain a more flexible flow, and the density is simply modified with products of determinants:
\[p_x(\mathbf{x}) = p_u(T^{-1}(\mathbf{x}))\prod_{k = 1}^K\left\vert \text{det } \mathbf{J}_{T_k^{-1}}(\mathbf{x}) \right\vert\]This nice property has been exploited for density estimation in high dimensional spaces with complicated distributions, such as images. By mapping them back to a simple distribution using a normalizing flow, we can optimize the parameters $\theta$ of a generative model by maximizing its log-likelihood $\log p_x(\mathbf{x};\theta)$. In particular, for a dataset with $N$ observations, we want to maximize
\[\log \prod_{i=1}^N p(\mathbf{x}^{(i)};\theta) = \sum_{i = 1}^N\log p_u(T^{-1}(\mathbf{x}^{(i)});\theta) + \sum_{k=1}^K\log\vert\text{det }\mathbf{J}_{T_k^{-1}}(\mathbf{x}^{(i)}; \theta)\vert\tag{2}\]Note that the parameters of the model can be the parameters of the base density $p_u(\mathbf{u})$ (such as the mean and covariance), as well as any parameters involved in the transformation $T$.
Once we have trained a model with normalizing flows, we have a generative model that we can use to
- Evaluate the density $p_x(\mathbf{x})$ for a new observation
- Generate samples that look like observations used for training, by sampling $\mathbf{u}\sim p_u(\mathbf{u})$ and passing it through the flow to get $\mathbf{x} = T(\mathbf{u})$.
There is one last caveat to mention before we can actually use normalizing flows with neural networks: the determinant of the Jacobian. In general, computing the determinant of a $D\times D$ requires a computation proportional to $D^3$, which can become unfeasible for large $D$. There is a special case, however. For a triangular matrix, the determinant reduces to the product of its elements in the diagonal. This then turns the amount of computation proportional to $D$. The reduction from cubic to linear complexity is a key motivator for the use of normalizing flows in machine learning.
Implementing tractable flows
One way to implement a normalizing flow that results in a triangular Jacobian is to use coupling layers, introduced by Dihn et al. (2015). A coupling layer leaves the first $d$ elements unchanged, and the rest of the elements are linearly transformed with a (possibly nonlinear) function of the first $d$ elements. More formally, if $\mathbf{z}$ is the input vector and by $\mathbf{z}_{1:d}$ we denote a slice of the first $d$ elements, a coupling layer implements the following equations to produce the output vector $\mathbf{z}’$:
\[\begin{align} \mathbf{z}'_{1:d} &= \mathbf{z}_{1:d} \\ \mathbf{z}'_{d+1:D} &= \mathbf{z}_{d+1:D}\odot\exp(s(\mathbf{z}_{1:d})) + t(\mathbf{z}_{1:d}) \end{align}\]where $\odot$ denotes element-wise multiplication, and $s$ and $t$ are scaling and translation functions that can be implemented with neural networks.
We may now ask two questions:
1) What is the inverse of this transformation? We can easily invert the two equations above to obtain
\[\begin{align} \mathbf{z}_{1:d} &= \mathbf{z}_{1:d}' \\ \mathbf{z}_{d+1:D} &= (\mathbf{z}_{d+1:D}' - t(\mathbf{z}_{1:d}'))\odot\exp(-s(\mathbf{z}_{1:d}')) \end{align}\]2) What is the determinant of the Jacobian? Since the first $d$ elements of the output are the same as the input, there will be a $d\times d$ block in the Jacobian containing an identity matrix. The remaining elements only depend on the first $d$, and themselves, so the Jacobian is triangular with the following structure:
\[\mathbf{J}(\mathbf{z}) = \begin{bmatrix} \mathbf{I} & \mathbf{0} \\ \mathbf{A} & \text{diag}(\exp(s(\mathbf{z}_{1:d}))) \end{bmatrix}\]In this case, $\mathbf{A}$ is a matrix of derivatives we don’t care about, and the determinant reduces to the products of the diagonal in the matrix $\text{diag}(\exp(s(\mathbf{z}_{1:d})))$, that simplifies further when computing the logarithm:
\[\begin{align} \log\vert\text{det }\mathbf{J}(\mathbf{z})\vert &= \log\prod_{i=1}^d \exp(s(\mathbf{z}_{1:d})_i) \\ &= \sum_{i=1}^d s(\mathbf{z}_{1:d})_i \end{align}\]Lastly, for the inverse of the transformation we have
\[\log\vert\det\mathbf{J}(\mathbf{z})\vert^{-1} = -\sum_{i=1}^d s(\mathbf{z}_{1:d})_i\]We now have all the ingredients to implement a coupling layer. To select only some parts of the input we will use a binary tensor to mask values, and for the scaling and translation functions we will use a 2-layer MLP, sharing parameters for both functions.
import torch.nn as nn
class Coupling(nn.Module):
def __init__(self, dim, num_hidden, mask):
super().__init__()
# The MLP for the scaling and translation functions
self.nn = torch.nn.Sequential(nn.Linear(dim // 2, num_hidden),
nn.ReLU(),
nn.Linear(num_hidden, num_hidden),
nn.ReLU(),
nn.Linear(num_hidden, dim))
# Initialize the coupling to implement the identity transformation
self.nn[-1].weight.data.zero_()
self.nn[-1].bias.data.zero_()
self.register_buffer('mask', mask)
def forward(self, z, log_det, inverse=False):
mask = self.mask
neg_mask = ~mask
# Compute scale and translation for relevant inputs
s_t = self.nn(z[:, mask])
s, t = torch.chunk(s_t, chunks=2, dim=1)
if not inverse:
z[:, neg_mask] = z[:, neg_mask] * torch.exp(s) + t
log_det = log_det + torch.sum(s, dim=1)
else:
z[:, neg_mask] = (z[:, neg_mask] - t) * torch.exp(-s)
log_det = log_det - torch.sum(s, dim=1)
return z, log_det
Now that we have defined a module for a coupling layer, we can use composition of coupling layers to build a normalizing flow.
We will use the forward method of the flow to compute the density of an observation $\mathbf{x}$ following equation 2. Additionally, we will define a sample method that takes a sample from the base distribution $p_u(\mathbf{u})$ and passes it through the flow in the inverse direction to obtain what would be a sample from the target distribution. These two methods traverse the flow in one or another direction, which we define in the transform method.
There are two practicalities yet to define at this point. First, even though we defined the coupling layer as transforming the input from index $d+1$ to $D$, in practice it’s usual to compose flows that alternate the dimensions that are transformed, with those that are not. Here we use binary masks of the form
\[[1, 0, 1, 0, ...]\]For the following coupling layer, we use the negated mask
\[[0, 1, 0, 1, ...]\]This gives a chance to the flow for transforming all dimensions in the input.
The second practicality has to do with the base distribution $p_u(\mathbf{u})$. If we use a standard Gaussian distribution, the log-probability is
\[\begin{align} \log p_u(\mathbf{u}) &= \log\left(\frac{1}{(2\pi)^{D/2}}\exp\left\lbrace-\frac{1}{2}\mathbf{u}^\top\mathbf{u}\right\rbrace\right) \\ &= -\frac{D}{2}\log(2\pi) - \frac{1}{2}\mathbf{u}^\top\mathbf{u} \end{align}\]We now have all the ingredients to implement the Normalizing Flow:
import torch
import numpy as np
class NormalizingFlow(nn.Module):
def __init__(self, dim, num_flows, num_hidden):
super().__init__()
# Create mask with alternating pattern
mask = torch.tensor([1, 0], dtype=torch.bool).repeat(dim // 2)
self.layers = nn.ModuleList()
for i in range(num_flows // 2):
self.layers.append(Coupling(dim, num_hidden, mask))
self.layers.append(Coupling(dim, num_hidden, ~mask))
# The initial value of the log-determinant is 0
self.register_buffer('init_log_det', torch.zeros(1))
self.dim = dim
def transform(self, z, inverse=False):
log_det = self.init_log_det
if not inverse:
for layer in self.layers:
z, log_det = layer(z, log_det)
else:
for layer in reversed(self.layers):
z, log_det = layer(z, log_det, inverse=True)
return z, log_det
def forward(self, x):
u, log_det = self.transform(x)
log_pu = -0.5 * self.dim * (np.log(2.0 * np.pi) + (u ** 2).sum(dim=1))
# Equation 2
log_px = log_pu + log_det
# Return the negative for minimization
return -log_px
def sample(self, num_samples):
# Sample from base (Gaussian) distribution
# and transform with flow
u = torch.randn((num_samples, self.dim))
x, _ = self.transform(u, inverse=True)
return x
Training the model
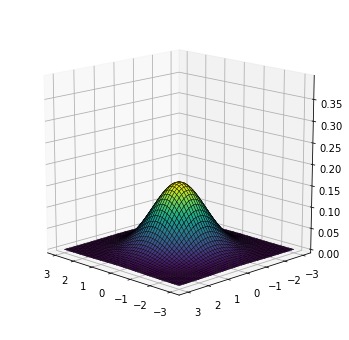
For visualization purposes, we will train a model for a very simple case where the data lies in a 2-dimensional space. Following our implementation, the base distribution is a standard Gaussian:
from utils import base, target, plot_density
plot_density(base)
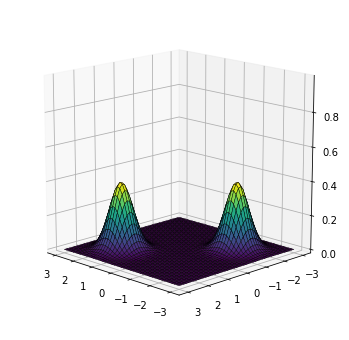
The target is a bimodal Gaussian distribution, with one mode at $(1.5, 1.5)$, and another at $(-1.5, -1.5)$:
plot_density(target)
For training, we will collect 2,000 samples from the target distribution.
from torch.utils.data import TensorDataset, DataLoader
dataset = TensorDataset(target.sample(2000))
loader = DataLoader(dataset, batch_size=64)
Since the dimension of the space where the data lies is just 2 and the target density is not too complicated, the model shouldn’t be too big. Here we will train a model composed of 4 transformations, where the 2-layer MLPs used for the coupling layers have 8 hidden units.
flow = NormalizingFlow(dim=2, num_flows=4, num_hidden=8)
We’re now ready to train the model! We will use Adam to train for 100 epochs. For each mini-batch, the value returned by the flow model is the negative log-likelihood for each sample. The loss that we minimize is then the mean across samples in the mini-batch.
import matplotlib.pyplot as plt
from torch.optim import Adam
optimizer = Adam(flow.parameters())
num_epochs = 100
losses = np.zeros(num_epochs)
for epoch in range(num_epochs):
for data in loader:
loss = flow(data[0]).mean()
optimizer.zero_grad()
loss.backward()
optimizer.step()
losses[epoch] += loss.item()
losses[epoch] /= len(loader)
plt.plot(losses)
plt.xlabel('Epochs')
plt.ylabel('Negative log-likelihood');
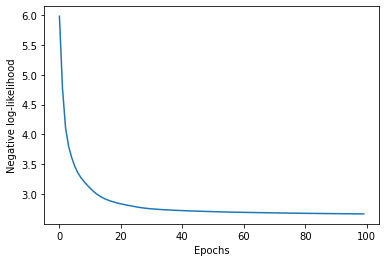
Now that the model is trained, we can draw samples from it. Since these are samples in 2-D space, we can draw them in a scatter plot, with some crosses to indicate the locations of the two modes in the target density:
samples = flow.sample(200).detach().cpu()
plt.scatter(samples[:, 0], samples[:, 1], label='Samples')
plt.scatter([1.5, -1.5], [1.5, -1.5], label='True modes')
plt.legend();
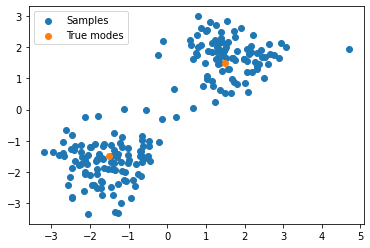
It seems the model has learned about the two modes!
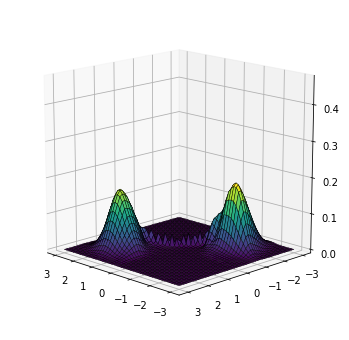
As mentioned before, an interesting property of this use of normalizing flows is that in addition of generating samples, we can also evaluate the density at any point in space. We can use this to evaluate the density on a fine grid of points to have a better understanding of the density learned by the model.
from utils import make_mesh, plot_surface
x1, x2, x = make_mesh()
# The model returns the negative log-density,
# so we negate it and take the exponential
log_px = -flow(x.reshape(-1, 2))
log_px = log_px.reshape(x.shape[:2]).detach()
px = log_px.exp()
plot_surface(x1, x2, px)
Alternatively, we can plot a contour map, as if we were looking at the density from above:
plt.imshow(px)
plt.axis('off');
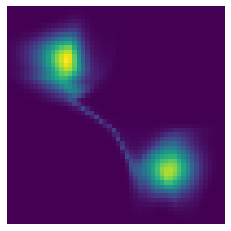
In spite of some artifacts in the center of the region, the model has clearly learned a density with two main modes located at the correct positions.
Wrapping it up
Normalizing flows are a general mechanism that allows us to model complicated distributions, when we have access to a simple one. They have been applied to problems of variational inference, where they can serve as flexible approximate posteriors [1, 2, 3], and also for density estimation, particularly applied to image data [4, 5]. Among other topics, current work is focusing on building more expressive, yet still tractable normalizing flows [6, 7], and other formulations, such as continuous flows that are modeled as an ordinary differential equation [8]. If you are interested in diving deeper into this area, I highly recommend two recent surveys on the matter [9, 10].
References
[1] Rezende, D. J., & Mohamed, S. (2015). Variational inference with normalizing flows. arXiv preprint arXiv:1505.05770.
[2] Berg, R. V. D., Hasenclever, L., Tomczak, J. M., & Welling, M. (2018). Sylvester normalizing flows for variational inference. arXiv preprint arXiv:1803.05649.
[3] Kingma, D. P., Salimans, T., Jozefowicz, R., Chen, X., Sutskever, I., & Welling, M. Improving variational inference with inverse autoregressive flow. (NeurIPS), 2016. URL http://arxiv.org/abs/1606.04934.
[4] Dinh, L., Sohl-Dickstein, J., & Bengio, S. (2016). Density estimation using real nvp. arXiv preprint arXiv:1605.08803.
[5] Kingma, D. P., & Dhariwal, P. (2018). Glow: Generative flow with invertible 1x1 convolutions. In Advances in neural information processing systems (pp. 10215-10224).
[6] Huang, C. W., Krueger, D., Lacoste, A., & Courville, A. (2018). Neural autoregressive flows. arXiv preprint arXiv:1804.00779.
[7] De Cao, N., Titov, I., & Aziz, W. (2019). Block neural autoregressive flow. arXiv preprint arXiv:1904.04676.
[8] Grathwohl, W., Chen, R. T., Bettencourt, J., Sutskever, I., & Duvenaud, D. (2018). FFJORD: Free-form continuous dynamics for scalable reversible generative models. arXiv preprint arXiv:1810.01367.
[9] Papamakarios, G., Nalisnick, E., Rezende, D. J., Mohamed, S., & Lakshminarayanan, B. (2019). Normalizing flows for probabilistic modeling and inference. arXiv preprint arXiv:1912.02762.
[10] Kobyzev, I., Prince, S., & Brubaker, M. (2020). Normalizing flows: An introduction and review of current methods. IEEE Transactions on Pattern Analysis and Machine Intelligence.